Как я случайно построил систему оркестрации LLM в браузере
Архитектурный разбор того, как Litseller использовал GPT API, React и промпты для оркестрации генерации структурированного контента прямо в браузере.
Эта статья продолжает идеи, которые я начал раскрывать в:
Про инстинкт самозванца, суперсилу и честный разворотДва года назад я сделал Litseller.
В тот момент я не думал про оркестрацию LLM или архитектуру таких систем. Я просто решал конкретную задачу: как быстро генерировать структурированный контент для каталога книг.
Сейчас, оглядываясь назад, я понимаю, что по сути это была полноценная система оркестрации LLM. Просто она была реализована не на backend, а прямо в браузере.
Что это было на самом деле
Важно правильно задать рамку.
Litseller не был LLM-сервисом.
Это было классическое веб-приложение с каталогом, поверх которого я встроил LLM как инструмент генерации данных в админке.
Вся оркестрация происходила в простом флоу: интерфейс редактора, GPT API, JSON, валидация и сохранение в backend.
- Без очередей.
- Без воркеров.
- Без серверной оркестрации.
- Без сложной инфраструктуры.
Всё держалось на React, промптах и цепочках запросов.
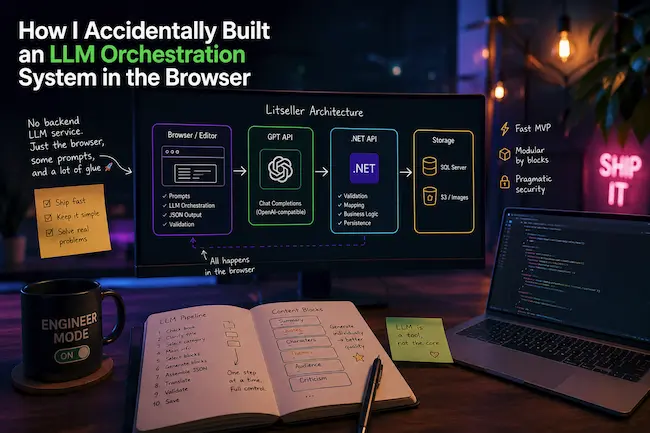
Архитектура
Система делилась на три слоя.
- Frontend: админка на Next.js, editor и вся LLM-логика.
- Backend: .NET API, валидация и сохранение.
- Хранилище: SQL Server и S3.
LLM-логика вообще не находилась на backend. Вызовы шли напрямую из браузера.
Pipeline генерации
Вместо одного большого запроса я построил pipeline.
- Проверка, знает ли модель книгу.
- Уточнение названия при необходимости.
- Выбор категории.
- Генерация основной информации.
- Выбор блоков контента, таких как summary, цитаты, темы и другие разделы.
- Генерация каждого блока отдельно.
- Сборка JSON.
- Перевод контента на другие языки.
- Валидация результата.
- Сохранение итоговых данных.
Это уже была полноценная оркестрация, просто без отдельного сервиса оркестрации.
Почему блоки сработали хорошо
Генерация контента по блокам стала одним из самых сильных решений.
Я не просил модель сгенерировать всю страницу книги сразу.
- Summary генерировался отдельно.
- Персонажи генерировались отдельно.
- Цитаты генерировались отдельно.
- Темы генерировались отдельно.
Это дало лучший контроль качества, возможность перегенерации отдельных частей, более стабильный JSON и меньше ошибок.
По сути это стало ручным слоем контроля версий над результатом работы LLM.
Prompt engineering
Промпты были простыми, но структурированными.
- Строгий JSON формат.
- Чёткие инструкции.
- Минимум магии.
Контекст передавался явно: название, автор, категории, язык и предыдущие блоки.
- Без памяти диалога.
- Без сложного состояния.
- Без tool calling.
Самое спорное решение
API ключ хранился в localStorage.
Причина была простой: это была админка, не публичный интерфейс, пользователей было очень мало, нужно было быстро запуститься, а backend-оркестрация сильно усложняла систему.
Это было осознанное решение. Риски были понятны и приняты.
Дополнительно доступ был ограничен и защищён вручную через Cloudflare.
Слабые стороны
Если смотреть честно сегодня, слабые стороны очевидны.
- API ключ на клиенте.
- Нет централизованного rate limiting.
- Нет централизованного контроля вызовов.
- Нет retry и backoff.
- Нет нормальной схемной валидации.
- Слабая обработка ошибок.
- Нет observability.
- Слишком сложная логика в браузере.
Это был сильный MVP, но не production-grade LLM платформа.
Сильные стороны
При этом система реально работала и давала результат.
- Очень быстрая разработка.
- Минимальная инфраструктура.
- Высокая гибкость.
- Полный контроль через UI.
- Удобная ручная доработка.
- Модульная генерация.
- Реальный production workflow.
LLM был инструментом, а не ядром системы.
Что бы я изменил сейчас
Если бы я делал это сегодня, я бы изменил архитектуру.
- Вынес бы LLM вызовы в backend gateway.
- Убрал бы API ключ с клиента.
- Добавил бы очереди и retries.
- Ввёл бы строгую JSON schema validation.
- Добавил бы логирование и трассировку.
- Сделал бы rate limiting.
- Разделил бы оркестрацию и UI.
Главный вывод
Самое интересное для меня в том, что я не проектировал LLM систему.
Я просто решал задачу.
И только потом понял, что собрал архитектуру, которую сейчас называют оркестрацией LLM.
Иногда хорошие инженерные решения сначала выглядят как хаос и интуиция. И только потом превращаются в понятную архитектуру, которую можно осознанно улучшать.