Cómo construí accidentalmente un sistema de orquestación LLM en el navegador
Una mirada arquitectónica a cómo Litseller utilizó la API de GPT, React y prompts para orquestar la generación de contenido estructurado desde el navegador.
Este artículo continúa las ideas que empecé a explorar en:
Sobre el instinto del impostor, la superpotencia y un giro honestoHace dos años construí Litseller.
En ese momento no pensaba en la orquestación de LLM ni en la arquitectura de este tipo de sistemas. Simplemente estaba resolviendo un problema concreto: cómo generar rápidamente contenido estructurado para un catálogo de libros.
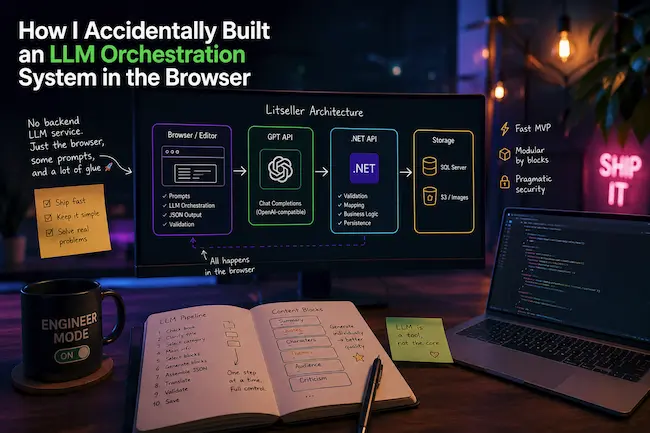
Ahora, mirando hacia atrás, entiendo que en esencia era un sistema completo de orquestación de LLM. Simplemente estaba implementado no en el backend, sino directamente en el navegador.
Qué era realmente
Es importante definir bien el contexto.
Litseller no era un servicio de LLM.
Era una aplicación web clásica con un catálogo, sobre la cual integré un LLM como herramienta de generación de datos dentro del panel de administración.
Toda la orquestación ocurría en un flujo simple: interfaz del editor, API de GPT, JSON, validación y guardado en el backend.
- Sin colas.
- Sin workers.
- Sin orquestación en el servidor.
- Sin infraestructura compleja.
Todo estaba construido sobre React, prompts y cadenas de solicitudes.
Arquitectura
El sistema se dividía en tres capas.
- Frontend: panel de administración en Next.js, editor y toda la lógica LLM.
- Backend: API en .NET, validación y persistencia.
- Almacenamiento: SQL Server y S3.
La lógica LLM no vivía en el backend en absoluto. Las llamadas se hacían directamente desde el navegador.
Pipeline de generación
En lugar de una sola solicitud grande, construí un pipeline.
- Verificar si el modelo conoce el libro.
- Aclarar el título si es necesario.
- Seleccionar una categoría.
- Generar la información principal.
- Seleccionar bloques de contenido como resumen, citas, temas y otras secciones.
- Generar cada bloque por separado.
- Construir el JSON.
- Traducir el contenido a otros idiomas.
- Validar el resultado.
- Guardar los datos finales.
Esto ya era una orquestación real, solo que sin un servicio de orquestación separado.
Por qué los bloques funcionaron bien
La generación de contenido por bloques fue una de las decisiones más fuertes.
No pedía al modelo generar toda la página del libro de una sola vez.
- El resumen se generaba por separado.
- Los personajes se generaban por separado.
- Las citas se generaban por separado.
- Los temas se generaban por separado.
Esto me dio mejor control de calidad, la posibilidad de regenerar partes individuales, un JSON más estable y menos errores.
En la práctica, se convirtió en una capa manual de control de versiones sobre la salida del LLM.
Ingeniería de prompts
Los prompts eran simples pero estructurados.
- Formato JSON estricto.
- Instrucciones claras.
- Mínima magia.
El contexto se pasaba explícitamente: título, autor, categorías, idioma y bloques anteriores.
- Sin memoria de conversación.
- Sin estado complejo.
- Sin tool calling.
La decisión más polémica
La clave de API se almacenaba en localStorage.
La razón era simple: el editor no era una interfaz pública, había muy pocos usuarios, la prioridad era lanzar rápido y la orquestación en backend habría hecho el sistema mucho más complejo.
Fue una decisión consciente. Los riesgos eran entendidos y aceptados.
Además, el acceso estaba restringido y protegido manualmente a través de Cloudflare.
Debilidades
Visto hoy de forma honesta, las debilidades son evidentes.
- Clave API en el cliente.
- Sin limitación centralizada de peticiones.
- Sin control centralizado de llamadas.
- Sin retry ni backoff.
- Sin validación de esquema adecuada.
- Manejo de errores débil.
- Sin observabilidad.
- Demasiada lógica compleja en el navegador.
Era un MVP fuerte, pero no una plataforma LLM de nivel production.
Fortalezas
Al mismo tiempo, el sistema funcionaba y producía resultados reales.
- Desarrollo muy rápido.
- Infraestructura mínima.
- Alta flexibilidad.
- Control total desde la interfaz.
- Refinamiento manual cómodo.
- Generación modular.
- Flujo real en producción.
El LLM era una herramienta, no el núcleo del sistema.
Qué cambiaría hoy
Si lo construyera hoy, cambiaría la arquitectura.
- Mover las llamadas LLM a un gateway en backend.
- Eliminar la clave API del cliente.
- Añadir colas y retries.
- Introducir validación estricta de JSON.
- Agregar logging y trazabilidad.
- Implementar rate limiting.
- Separar la orquestación de la UI.
Conclusión principal
Lo más interesante para mí es que no diseñé un sistema LLM.
Simplemente estaba resolviendo un problema.
Solo después entendí que había construido una arquitectura que hoy se llama orquestación de LLM.
A veces las buenas decisiones de ingeniería primero parecen caos e intuición. Solo después se convierten en una arquitectura clara que puede mejorarse conscientemente.